Recently helped a customer remove Cloudfront URLs as part of a migration process from AWS to Kinsta. Kinsta’s CDN is powered by Cloudflare and is built-in. There is no need for URLs to reference a CDN-specific location. So restoring all URL references back to their original location was required before shutting down the old AWS Cloudfront account.
Changing internal URL references is typically a one-liner with WP-CLI’ search-replace command. However, this one took some clever logic to get right due to the fact that it was a large multisite network and had extra formatting that needed to be handled in the URL itself. Here is a walkthrough of the steps I took.
Step #1 – Replace Cloudfront URLs per site
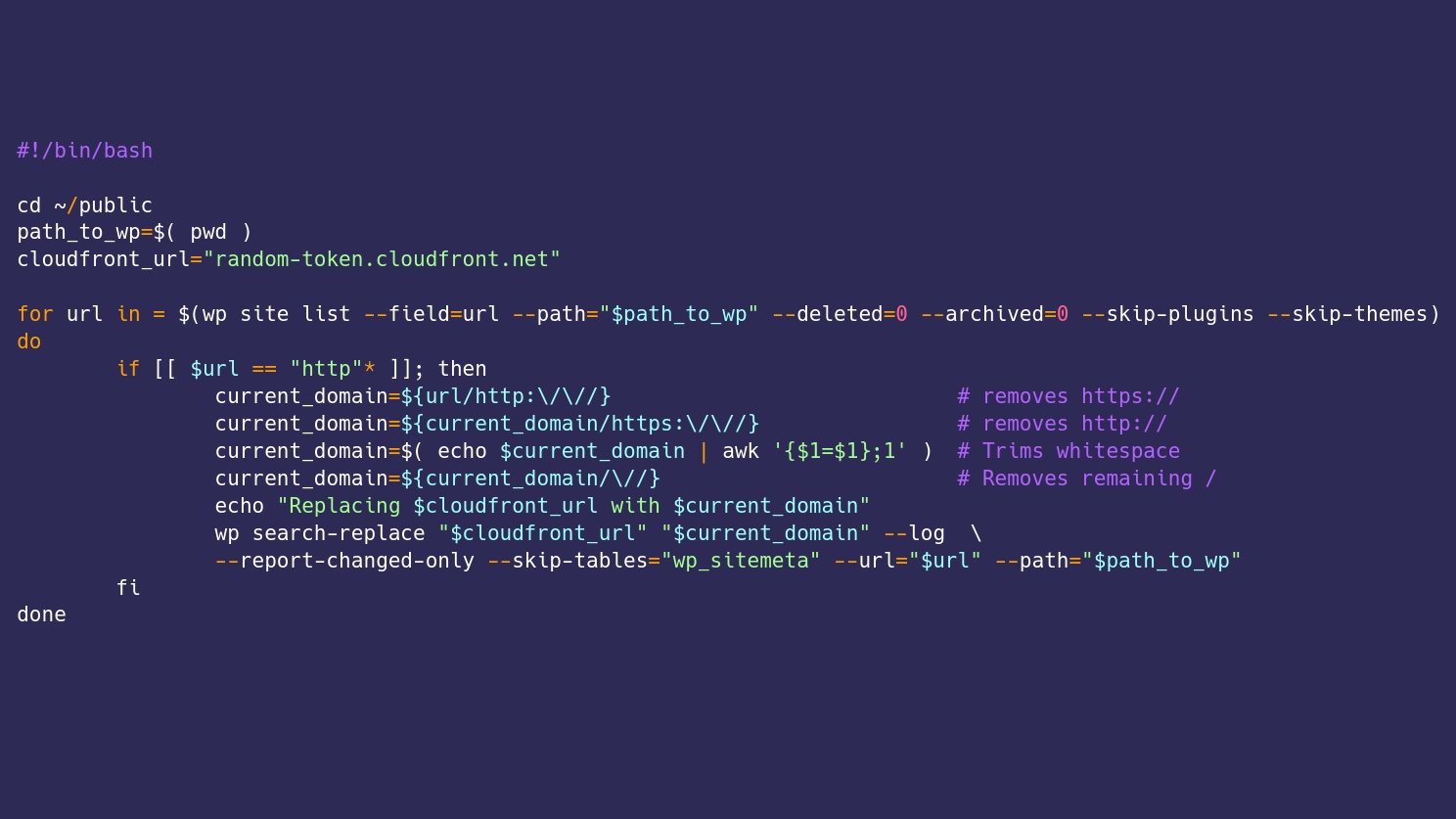
The problem is that URLs formatted like random-token.cloudfront.net were scattered throughout the multisite network. These references need to be replaced with each site’s domain which is unique per subsite. To do this properly I wrote the following replace-cloudfront-references.sh bash script to handle.
#!/bin/bash
cd ~/public
path_to_wp=$( pwd )
cloudfront_url="random-token.cloudfront.net"
for url in = $(wp site list --field=url --path="$path_to_wp" --deleted=0 --archived=0 --skip-plugins --skip-themes)
do
if [[ $url == "http"* ]]; then
current_domain=${url/http:\/\//} # removes https://
current_domain=${current_domain/https:\/\//} # removes http://
current_domain=$( echo $current_domain | awk '{$1=$1};1' ) # Trims whitespace
current_domain=${current_domain/\//} # Removes remaining /
echo "Replacing $cloudfront_url with $current_domain"
wp search-replace "$cloudfront_url" "$current_domain" --log --report-changed-only --skip-tables="wp_sitemeta" --url="$url" --path="$path_to_wp"
fi
doneRunning replace-cloudfront-references.sh loops through each site on the multisite network and runs a WP-CLI search and replace unique per each site. I did need to skip the global table wp_sitemeta so that bad references in there didn’t get changed through each loop.
Step 2 – Cleanup extra token in URLs
The Cloudfront URL format included extra data towards the end of the file name. For example, https://random-token.cloudfront.net/wp-content/uploads/sites/70/2020/08/53294582/main.jpg worked with Cloudfront however Cloudfront added the section right before the file name for security reasons. That extra section needs removed in order for the URLs to work now they are pointed back to their respective domains.
This can be handled with a regex search and replace like this. The --dry-run and --log flags are added for safety to verify the regex search is correct by previewing the replacements to be made.
wp search-replace "wp-content\/uploads\/(sites\/\d+\/\d{4}\/\d{2}\/)\d{8}\/" "wp-content/uploads/\1\2" --regex --dry-run --log --all-tables --report-changed-onlyRunning a regex search and replacement is a very slow and intensive process. Rather than targeting the entire database my final query only ran on tables I knew there to be Cloudfront URLs. Something closer to the following.
wp search-replace "wp-content\/uploads\/(sites\/\d+\/\d{4}\/\d{2}\/)\d{8}\/" "wp-content/uploads/\1\2" wp_*_options wp_*_postmeta wp_*_posts wp_*_hustle_modules_meta wp_*_layerslider --regex --dry-run --log --all-tables --report-changed-onlyWhen satisfied with the search and replacements to be made, last step is to remove --dry-run flag and run the final command.
Step #3 – Additional cleanup
While running the find and replace with the --log I noticed a few other places that needed to be changed. For example, I saw extra tokens removed for URLs referring to custom-bucket.s3.amazonaws.com. So I plugged that into the first script cloudfront_url=custom-bucket.s3.amazonaws.com and re-ran.