A customer’s WooCommerce store was crashing every afternoon. Not a little slow. Completely unreachable. 503 errors for eight minutes at a time, then it would come back, then crash again. This happened three times in a row during a single email campaign.
I had server logs. I had error logs. But none of them told me what was happening in real time while the site was under load. I needed to watch the server the way you’d watch a heart monitor. So I wrote one.
The whole thing fits in 11 lines of bash.
The monitor script runs in the background on the server, sampling three metrics every 30 seconds: database connections, server load average, and HTTP response time.
nohup bash /tmp/php-monitor.sh >> /tmp/php-monitor.log 2>&1 &Every 30 seconds, it writes a line like this:
10:29:07 | 4 | 0.27 | 200 0.055266sTime. Database connections. Load. HTTP status and response time. No agents, no SaaS dashboards, no monthly fees. Just a bash script, a log file, and SSH.
Here is the full standalone script. It pulls database credentials from wp-config.php automatically. The only thing to fill in is the domain.
#!/bin/bash
# Lightweight server performance monitor
# Samples every 30 seconds: DB connections, load, response time, PHP workers
#
# Deploy to ~/private/php-monitor.sh then start with:
# nohup bash ~/private/php-monitor.sh >> ~/private/php-monitor.log 2>&1 &
# Pull database credentials from wp-config.php
SITE_PATH="$HOME/public"
DB_USER=$(grep DB_USER "$SITE_PATH/wp-config.php" | cut -d"'" -f4)
DB_PASS=$(grep DB_PASSWORD "$SITE_PATH/wp-config.php" | cut -d"'" -f4)
DOMAIN="example.com" # Replace with your site domain
while true; do
CONNS=$(mysql -u "$DB_USER" -p"$DB_PASS" -N -e \
"SELECT COUNT(*) FROM information_schema.processlist WHERE user='$DB_USER'" 2>/dev/null)
LOAD=$(uptime | awk -F'load average:' '{print $2}' | awk -F, '{print $1}' | xargs)
RESP=$(curl -kILs --max-time 10 -H "Host: $DOMAIN" \
https://localhost/ -o /dev/null -w '%{http_code} %{time_total}s' 2>/dev/null)
WORKERS=$(pgrep -u "$(whoami)" -c php-fpm 2>/dev/null || echo 0)
echo "$(date '+%H:%M:%S') | ${CONNS:-0} | $LOAD | $RESP | $WORKERS"
sleep 30
doneA companion check script runs via cron every 10 minutes to make sure the monitor is still alive. If it stalls, it restarts automatically.
#!/bin/bash
# Save as ~/private/php-monitor-check.sh
# Add to crontab: */10 * * * * bash ~/private/php-monitor-check.sh
pgrep -f 'php-monitor.sh' > /dev/null || \
nohup bash ~/private/php-monitor.sh >> ~/private/php-monitor.log 2>&1 &The first thing I learned was that the server was fine. Mostly.
I deployed the monitor on the customer’s server and let it run. Overnight, the numbers were calm. One to three database connections. Load around 5-6. Response times under a second.
Then 10:30 AM hit. Every single weekday, like clockwork, the server would start climbing. Database connections would ramp from 7 to 20 to 30. The load would spike past 12. And when connections hit 50, the server stalled completely.
The ceiling was not traffic. It was PHP workers. The shared hosting environment capped PHP-FPM at 32 workers. Once every worker was busy, new requests queued up and eventually timed out. The database connection count was really a proxy for the number of PHP processes actively running.
Newsletter blasts were the trigger.
The customer used Klaviyo for email marketing. When they sent a campaign to their 50,000+ subscriber list, something interesting happened. Email clients like Gmail and Outlook automatically prefetch every link in an email for security scanning. Each prefetched link included a unique per-subscriber tracking parameter, which meant every single request bypassed the CDN cache and hit the origin server directly.
I asked Claude Code to dig into the access logs during the outage.
The monitor captured the exact moment of collapse. Within 30 seconds of the campaign going out, database connections jumped from 7 to 50+. Load spiked past 20. Response times went from 40 milliseconds to full timeouts.
First wave: 1,665 requests in a single minute. Over the next hour, 6,422 Klaviyo click-throughs hit the server. The site went down three separate times across a three-hour window.
64 plugins and a tracking problem.
The monitor data helped me trace the problem deeper. This site ran 64 active plugins on an 18GB database with 600,000+ WooCommerce orders. Every request had to load all of that.
But the real offender was a tracking plugin. PixelYourSite was firing Facebook Pixel and GA4 events on every page load, then making a secondary AJAX callback to pull WooCommerce data server-side. That added 2.15 seconds to every single request. When the server was already saturated from newsletter traffic, those extra AJAX calls were the difference between slow and down.
I deactivated the tracking plugin. The monitor showed the difference immediately. Response times dropped, and the server stayed up through the next traffic spike.
I left the monitor running for 38 days.
Over those 38 days, the monitor collected 87,000 samples. I could see every traffic pattern, every cron job spike, every quiet overnight period. The data told a clear story.
Peak days hit 829 orders. Over the full 38 days, the site processed over 12,000 orders. The server handled most of it. But every weekday morning and every newsletter sent pushed it past its limits.
The shared hosting had a hard ceiling, and no amount of optimization would fix it. The site had outgrown the infrastructure.
Migration day was the real test.
We moved the site from shared hosting to dedicated infrastructure on Kinsta. I had the monitor running on both servers simultaneously. On migration day, the site processed 469 orders. The maintenance window lasted about 20 minutes.
I asked Claude Code to compare the data from both servers.
The numbers on the new dedicated server spoke for themselves.
Down from 9.3 average load, 2.6-second response times, 52 peak database connections, and regular timeouts on the old shared server.
Same traffic. Same plugins. Same database. The new server was essentially coasting through what used to cause crashes.
I left the monitor running overnight on the new server to make sure. 200 status codes across the board. Response times between 21-37ms all night. Orders kept processing without a single hiccup.
So I turned it into a real feature.
The bash script worked so well that I decided to build it into CaptainCore as a proper tool.
Now, any site can be monitored with a single command.
captaincore performance-monitor activate <site>
captaincore performance-monitor deactivate <site>
captaincore performance-monitor fetch <site>The activate command SSHs into the server, deploys the monitor script and the cron-based health check, and starts collecting data. The deactivate command stops everything cleanly. And fetch pulls the log file, parses it, and returns structured JSON with all the samples.
The dashboard makes the data useful.
Raw log lines are great for debugging but terrible for spotting trends. I built a Chart.js dashboard that visualizes all the metrics in real time. Four synchronized charts. Database connections, server load, response time, and PHP workers. Hover over a spike on one chart, and a crosshair appears on all four at the same timestamp.
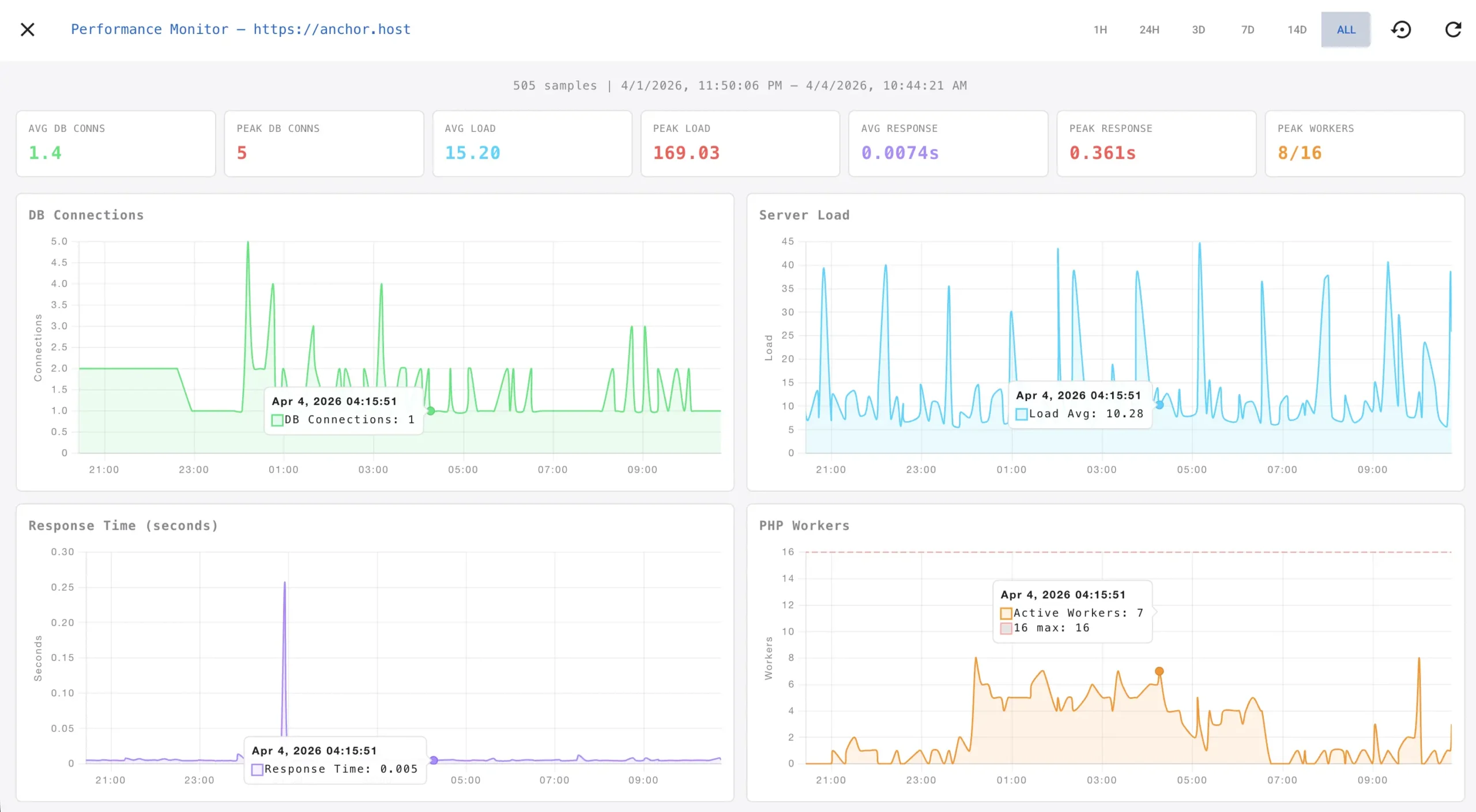
Time range filters let you zoom from one hour to 14 days. A dark theme keeps it easy on the eyes during late-night debugging sessions.
The dashboard lives right in the CaptainCore manager UI. Click into any site, open the Stats tab, toggle the performance monitor on, and you are watching live data within 30 seconds.
It also caught problems I was not looking for.
On another site, the CaptainCore health monitor was flip-flopping. Alerts would fire, saying the HTML was invalid, and then immediately send a recovery notification. Over and over, every few minutes.
I deployed the performance monitor to investigate. Server load was 9.23 on 12 cores, mostly I/O wait. Something was hammering the disk. The monitor data pointed me to a spam filtering plugin making heavy self-referential HTTP requests that bypassed caching. Each one took 12 seconds. Disabling that single feature stabilized the server.
Without the monitor, I would have been guessing.
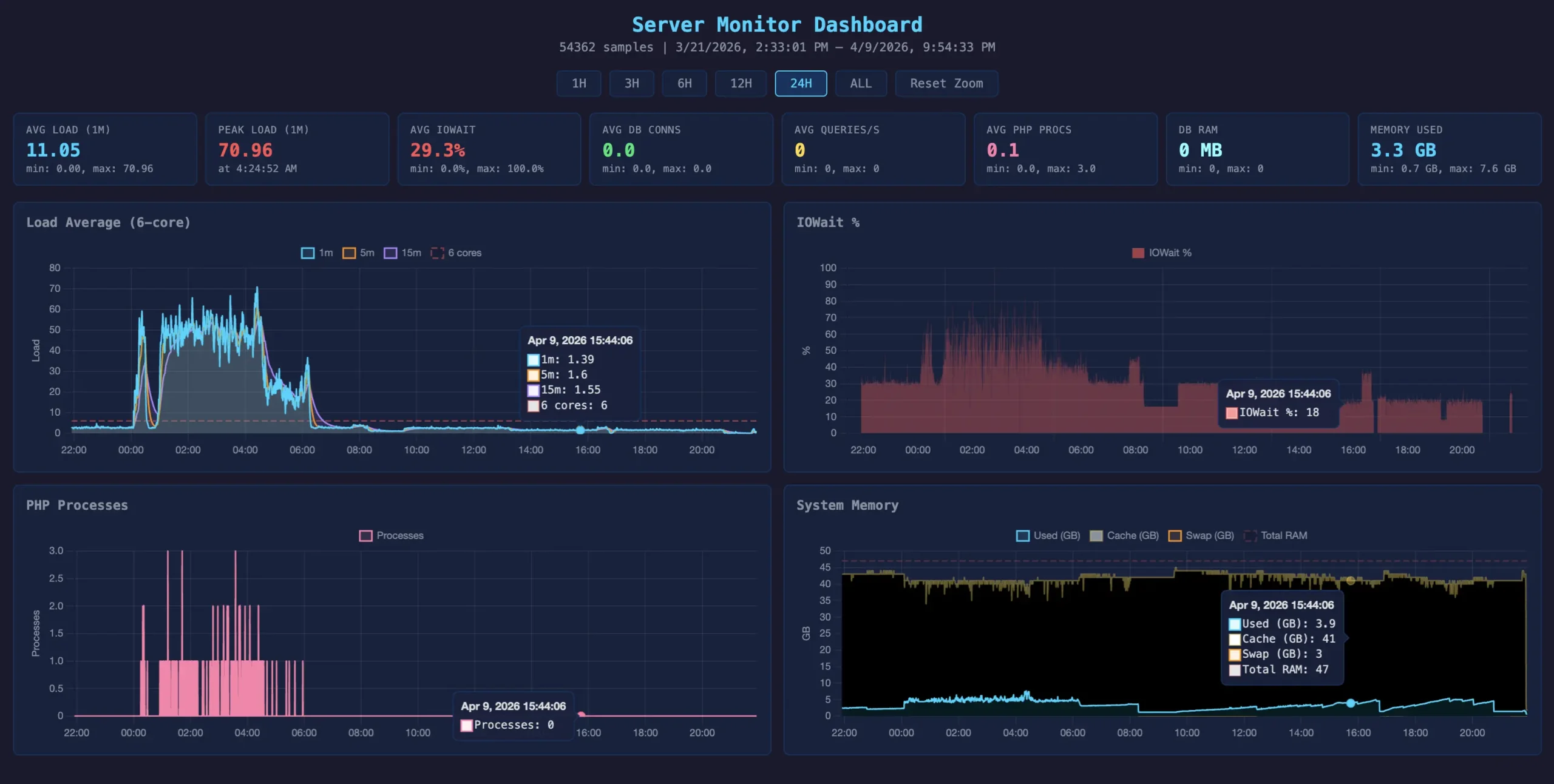
I also built one for the CaptainCore server itself.
The same concept scales up. I built a server-level version that tracks additional metrics for the CaptainCore infrastructure: database queries per second, memory usage, swap, I/O wait, and PHP process counts.
It revealed that the old PHP-based monitoring system was leaking memory. One process had consumed 35GB of RAM before triggering the OOM killer. That discovery pushed me to rebuild the monitoring in Go and eliminate the leak entirely.
Lightweight monitoring changes how you make decisions.
The performance monitor started as a quick hack to understand why a site was crashing. It ended up changing how I approach every hosting decision. Migration planning. Plugin evaluation. Traffic spike diagnosis. Server sizing.
Every site I manage now has this available at the click of a button. Deploy it when something feels off. Leave it running during a migration. Turn it on before a big sale. The monitor sees what the server sees, in real time, and that changes everything.